1부 딥러닝의 기초
3장 신경망 시작하기
3.4 영화 리뷰 분류: 이진 분류 예제
IMDB 데이터셋 (Internet Movie Database)
인터넷 영화 데이터베이스로부터 가져온 양극단의 리뷰 5만 개로 이루어짐.
훈련 데이터 2만 5,000개와 테스트 데이터 2만 5,5000개로 나뉘어 있고
각각 50%는 부정, 50%는 긍정 리뷰로 구성
각 리뷰(단어 시퀀스)가 숫자 시퀀스로 변환되어 있음.
1. 데이터셋 로드
from keras.datasets import imdb
#data load, rottnsms 1만 개로 제한
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)train_data, test_data : 리뷰의 목록, 각 리뷰는 단어 인덱스의 리스트
train_labels, test_labels : 부정을 나타내는 0과 긍정을 나타내는 1의 리스트
2.데이터 준비
숫자 리스트에서 텐서로 변경하는 2가지 방법
(1) 같은 길이가 되도록 리스트에 패딩(pading)을 추가하고 (sample, sequence_length)크기의 정수 텐서로 변환
그 다음 정수 텐서를 다룰 수 있는 층을 신경망의 첫 번째 층으로 사용(Embedding 층)
(2) 리스트를 원-핫 인코딩(one-hot encoding)하여 0과 1의 벡터로 변환
시퀀스[3, 5]를 인덱스 3과 5의 위치는 1이고 그 외는 모두 0인 10,000차원의 벡터로 각각 변환
그 다음 부동 소수 벡터 데이터를 다룰 수 있는 Dense층을 신경망의 첫 번째 층으로 사용
#(2)방법 사용
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
# 크기가 (len(sequences), dimension))이고 모든 원소가 0인 행렬을 만듦.
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # results[i]에서 특정 인덱스의 위치를 1로 만듦.
return results
# 훈련 데이터를 벡터로 변환
x_train = vectorize_sequences(train_data)
# 테스트 데이터를 벡터로 변환
x_test = vectorize_sequences(test_data)# 레이블을 벡터로 변환
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
3. 신경망 모델 만들기 - 모델 정의하기
relu함수
입력 데이터가 벡터고 레이블은 스칼라(1 또는 0)과 같은 문제에 잘 작동하는 네트워크 종류는 relu 활성화 함수를 사용한 완전 연결층(Dense(16, activation='relu'))을 그냥 쌓은 것
Dense층에 전달한 매개변수(16)는 은닉 유닛(hidden unit)의 개수
하나의 은닉 유닛은 층이 나타내는 표현 공간에서 하나의 차원이 됨.
output = relu(dot(W,input) + b)
16개의 은닉 유닛이 있다는 것은 가중치 행렬 W의 크기가 (input_dimension, 16)이라는 뜻
입력 데이터와 W를 점곱하면 입력 데이터가 16차원으로 표현된 공간으로 투영됨.
그리고 편향 벡터 b를 더하고 relu연산을 적용
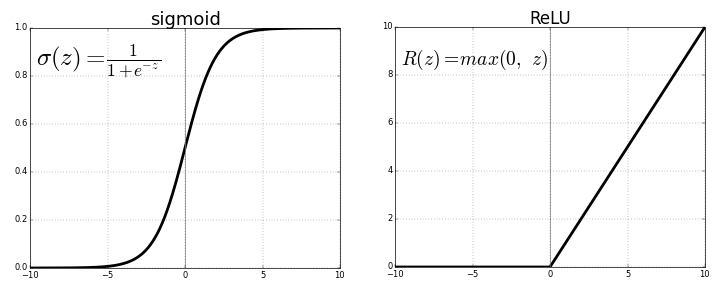
Dense층을 쌓을 때 두 가지 중요한 구조상의 결정이 필요
- 얼마나 많은 층을 사용할 것인가?
=> 16개의 은닉 유닛을 가진 2개의 은닉 층 - 각 층에 얼마나 많은 은닉 유닛을 둘 것인가?
=> 현재 리뷰의 감정을 스칼라 값의 예측으로 출력하는 세 번째 층
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))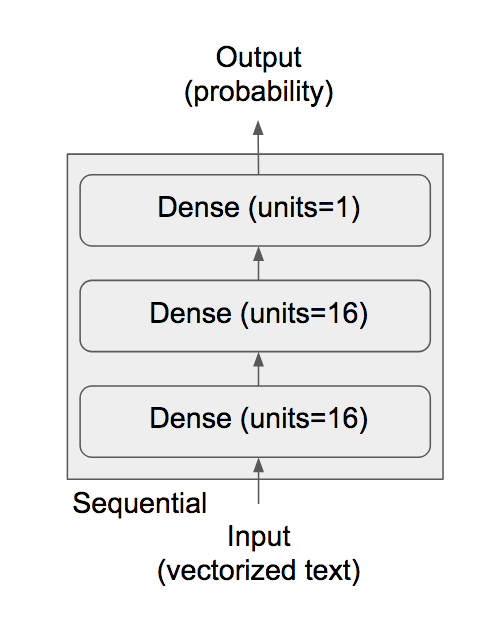
4. 신경망 모델 만들기 - 모델 컴파일하기
model.compile(optimizer='rmsprop', #옵티마이저 선택
loss='binary_crossentropy', #손실 함수 선택
metrics=['accuracy']) # 측정 지표 선택손실 함수에서 이진 분류 문제이고 신경망의 출력이 확률이므로 binary_crossentropy 또는 mean_squared_error가 적합
(확률 출력 모델은 크로스엔트로피(Crossentropy)가 적합)
크로스엔트로피(Crossentropy) : 정보 이론 분야에서 온 개념으로 확률 분포 간의 차이를 측정
5. 훈련 검증
훈련하는 동안 처음 본 데이터에 대한 모델의 정확도를 측정하기 위해 원본 훈련 데이터에서 10,000개의 샘플을 준비
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
512개의 샘플씩 미니 배치를 만들어 20번의 에포크 동안 훈련
x_train과 y_train 텐서에 있는 모든 샘플에 대해 20번 반복
동시에 따로 떼어 놓은 1만 개의 샘플에서 손실과 정확도를 측정하기 위해 validation_data 매개변수에 검증 데이터 넣기
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
훈련 검증 손실 그리기
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# ‘bo’는 파란색 점을 의미합니다
plt.plot(epochs, loss, 'bo', label='Training loss')
# ‘b’는 파란색 실선을 의미합니다
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
훈련과 검증 정확도 그리기
plt.clf() # 그래프를 초기화합니다
acc = history_dict['acc']
val_acc = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()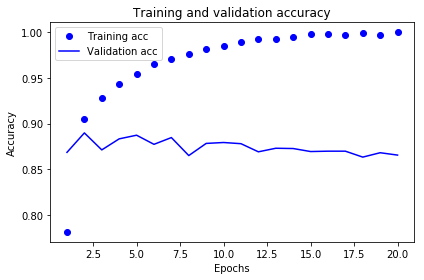
4번째 에포크 이후부터 훈련 데이터에 과도하게 최적화된 과대 적합(overfitting)인 걸 확인할 수 있음.
따라서, 에포크를 4번으로 줄이고 다시 훈련하기
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test, y_test)
최종 결과 : 87%의 정확도
>>> results
[0.3231545869159698, 0.87348]
6. 훈련된 모델로 새로운 데이터에 대해 예측하기
>>> model.predict(x_test)
array([[0.1402615 ],
[0.9997029 ],
[0.29552558],
...,
[0.07234979],
[0.04342841],
[0.48153415]], dtype=float32)'MLOps 프로젝트 > 도서 '케라스 창시자에게 배우는 딥러닝'' 카테고리의 다른 글
| 1부 3.6 주택 가격 분류: 회귀 문제 (0) | 2021.08.29 |
|---|---|
| 1부 3.5 뉴스 기사 분류: 다중 분류 예제 (0) | 2021.08.29 |
| 1부 3.3 딥러닝 컴퓨터 셋팅 (0) | 2021.08.28 |
| 1부 3.2 케라스 소개 (0) | 2021.08.28 |
| 1부 3.1 신경망의 구조 (0) | 2021.08.28 |