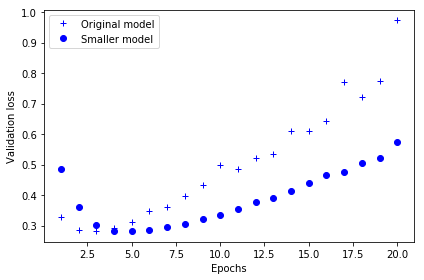
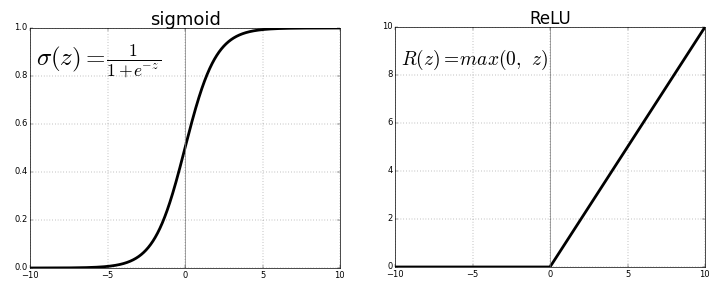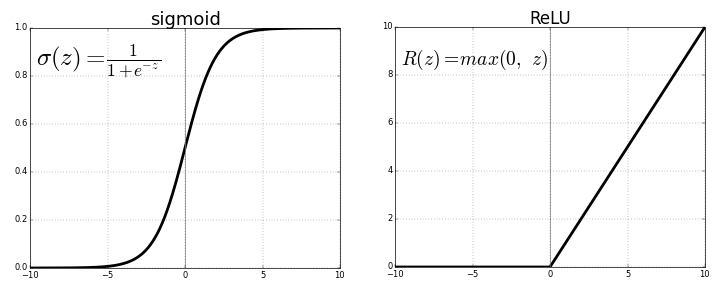2부 실전 딥러닝 5장 컴퓨터 비전을 위한 딥러닝 5.1 합성곱 신경망 소개 완전 연결된 모델보다 컨브넷이 더 잘 작동됨. Dense층은 입력 특성 공간에 있는 전역 패턴을 학습하지만 합성곱 층은 지역 패턴을 학습함. 이미지일 경우 작은 2D 윈도우로 입력에서 패턴을 찾음. 컨브넷의 2가지 성질 1. 학습된 패턴은 평행 이동 불변성을 가짐. 2. 컨브넷은 패턴의 공간적 계층 구조를 학습할 수 있음. 패딩 입력 특성 맵의 가장자리에 적절한 개수의 행과 열을 추가 입력과 동일한 높이와 너비를 가진 출력 특성 맵을 얻고 싶을 때 사용 (경계 문제를 해결해줌.) 스트라이드 두 번의 연속적인 윈도우 사이의 거리로 합성곱의 파라미터 기본값은 1이며 스트라이드가 1보다 큰 스트라이드 합성곱도 가능 스트라이드 2를 사..