1부 딥러닝의 기초
4장 머신 러닝의 기본 요소
4.4 과대적합과 과소적합
최적화(optimization)
가능한 훈련 데이터에서 최고의 성능을 얻으려고 모델을 조정하는 과정
일반화(generalization)
훈련된 모델이 이전에 본 적 없는 데이터에서 얼마나 잘 수행되는지 의미
과소적합(underfitting)
훈련 데이터의 손실이 낮아질수록 테스트 데이터의 손실도 낮아짐.
과대적합(overfitting)
훈련 데이터가 여러 번 반복 학습하고 나면 어느 시점붜 일반화 성능이 더 이상 높아지지 않고 검증 세트의 성능이 멈추고 감소되기 시작함.
훈련 데이터가 많으면 일반화 성능이 뛰어나짐.
규제 기법 종류
규제 기법
데이터를 더 모으는 것이 불가능할 때 차선책은 모델이 수용할 수 있는 정보의 양을 조절하거나 저장할 수 있는 정보에 제약을 가하는 것
네트워크 크기 축소
과대적합을 막는 가장 단순한 방법으로 모델의 크기, 즉 모델에 있는 학습 파라미터의 수를 줄이는 것
- 손실을 최소화하기 위해 타깃에 대한 예측 성능을 가진 압축된 표현을 학습해야 함.
- 동시에 기억해야할 것은 과소적합되지 않도록 충분한 파라미터를 가진 모델을 사용해야 한다는 점
- 모델의 기억 용량이 부족해서는 안 됨.
- 너무 많은 용량과 충분하지 않은 용량 사이의 절충점을 찾아야 함.
알맞은 층의 수나 각 층의 유닛 수를 결정할 수 있는 마법 같은 공식은 없음.
데이터에 알맞는 모델 크기를 찾으려면 각기 다른 구조를 (당연히 테스트 세트가 아니고 검증 세트에서) 평가해 보아야 함.
적절한 모델 크기를 찾는 일반적인 작업 흐름은 비교적 적은 수의 층과 파라미터로 시작
그다음 검증 손실이 감소되기 시작할 때까지 층이나 유닛의 수를 늘리는 것
영화 리뷰 분류 모델에 적용
#원본 모델
from keras import models
from keras import layers
original_model = models.Sequential()
original_model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
original_model.add(layers.Dense(16, activation='relu'))
original_model.add(layers.Dense(1, activation='sigmoid'))
original_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
original_hist = original_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
#더 작은 네트워크의 모델
smaller_model = models.Sequential()
smaller_model.add(layers.Dense(6, activation='relu', input_shape=(10000,)))
smaller_model.add(layers.Dense(6, activation='relu'))
smaller_model.add(layers.Dense(1, activation='sigmoid'))
smaller_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
smaller_model_hist = smaller_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))epochs = range(1, 21)
original_val_loss = original_hist.history['val_loss']
smaller_model_val_loss = smaller_model_hist.history['val_loss']import matplotlib.pyplot as plt
#‘b+’는 파란색 덧셈 기호을 의미
plt.plot(epochs, original_val_loss, 'b+', label='Original model')
#‘bo’는 파란색 점을 의미
plt.plot(epochs, smaller_model_val_loss, 'bo', label='Smaller model')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()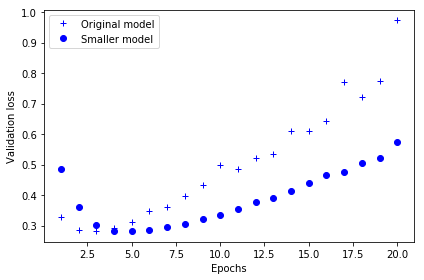
작은 네트워크(여섯 번째 에포크)가 기본 네트워크(네 번째 에포크)보다 에서 더 나중에 과대적합되기 시작
과대적합이 시작되었을 때 성능이 더 천천히 감소
#많은 용량을 가진 네트워크의 모델
bigger_model = models.Sequential()
bigger_model.add(layers.Dense(1024, activation='relu', input_shape=(10000,)))
bigger_model.add(layers.Dense(1024, activation='relu'))
bigger_model.add(layers.Dense(1, activation='sigmoid'))
bigger_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
bigger_model_hist = bigger_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))bigger_model_val_loss = bigger_model_hist.history['val_loss']
plt.plot(epochs, original_val_loss, 'b+', label='Original model')
plt.plot(epochs, bigger_model_val_loss, 'bo', label='Bigger model')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()
용량이 큰 네트워크는 첫 번째 에포크 이후 거의 바로 과대적합이 시작되어 갈수록 더 심해짐. (검증 손실도 매우 불안정)
#원본과 큰 네트워크의 훈련 손실
original_train_loss = original_hist.history['loss']
bigger_model_train_loss = bigger_model_hist.history['loss']
plt.plot(epochs, original_train_loss, 'b+', label='Original model')
plt.plot(epochs, bigger_model_train_loss, 'bo', label='Bigger model')
plt.xlabel('Epochs')
plt.ylabel('Training loss')
plt.legend()
plt.show()
용량이 큰 네트워크는 훈련 손실이 매우 빠르게 0에 가까워짐.
용량이 많은 네트워크일수록 더 빠르게 훈련 데이터를 모델링할 수 있음. (결국 훈련 손실이 낮아짐)
하지만 더욱 과대적합에 민감해짐. (결국 훈련과 검증 손실 사이에 큰 차이가 발생)
가중치 규제 추가
오캄의 면도날 이론
어떤 것에 대한 두 가지의 설명이 있다면 더 적은 가정을 필요하는 간단한 설명이 옳을 것이라는 이론
이 개념은 신경망으로 학습되는 모델에도 적용
어떤 훈련 데이터와 네트워크 구조가 주어졌을 때 데이터를 설명할 수 있는 가중치 값의 집합은 여러 개(여러 개의 모델)
간단한 모델(파라미터 값 분포의 엔트로피가 작은 모델)이 복잡한 모델보다 덜 과대적합될 가능성이 높음.
그러므로 과대적합을 완화시키기 위한 일반적인 방법은 네트워크의 복잡도에 제한을 두어 가중치가 작은 값을 가지도록 강제하는 것
가중치 규제
가중치 값의 분포가 더 균일하게 됨.
네트워크의 손실 함수에 큰 가중치에 연관된 비용을 추가하며 두 가지 형태의 비용 존재
- L1 규제 : 가중치의 절대값에 비례하는 비용이 추가(가중치의 L1 노름).
- L2 규제(가중치 감쇠) : 가중치의 제곱에 비례하는 비용이 추가(가중치의 L2 노름)
영화 리뷰 분류 네트워크에 L2 가중치 규제를 추가해보기
from keras import regularizers
l2_model = models.Sequential()
l2_model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu', input_shape=(10000,)))
l2_model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu'))
l2_model.add(layers.Dense(1, activation='sigmoid'))
l2_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
l2_model_hist = l2_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))l2_model_val_loss = l2_model_hist.history['val_loss']
plt.plot(epochs, original_val_loss, 'b+', label='Original model')
plt.plot(epochs, l2_model_val_loss, 'bo', label='L2-regularized model')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()
두 모델이 동일한 파라미터 수를 가지고 있더라도 L2 규제를 사용한 모델(점)이 기본 모델(덧셈 기호)보다 훨씬 더 과대적합에 잘 견디고 있음을 확인할 수 있음.
드롭아웃 추가
신경망을 위해 사용되는 규제 기법 중에서 가장 효과적이고 널리 사용되는 방법 중 하나
네트워크 층에 드롭아웃을 적용하면 훈련하는 동안 무작위로 층의 일부 출력 특성을 제외시킴. (0으로 만듦.)
IMDB 네트워크에 두 개의 `Dropout` 층을 추가하고 과대적합을 얼마나 줄여주는지 확인해보기
dpt_model = models.Sequential()
dpt_model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
dpt_model.add(layers.Dropout(0.5))
dpt_model.add(layers.Dense(16, activation='relu'))
dpt_model.add(layers.Dropout(0.5))
dpt_model.add(layers.Dense(1, activation='sigmoid'))
dpt_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
dpt_model_hist = dpt_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))dpt_model_val_loss = dpt_model_hist.history['val_loss']
plt.plot(epochs, original_val_loss, 'b+', label='Original model')
plt.plot(epochs, dpt_model_val_loss, 'bo', label='Dropout-regularized model')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()
여기에서도 기본 네트워크보다 확실히 향상됨을 확인할 수 있음.
'MLOps 프로젝트 > 도서 '케라스 창시자에게 배우는 딥러닝'' 카테고리의 다른 글
| 2부 5.1 합성곱 신경망 소개 (0) | 2021.09.01 |
|---|---|
| 1부 4.5 보편적인 머신 러닝 작업 흐름 (0) | 2021.09.01 |
| 1부 4.3 데이터 전처리, 특성 공학, 특성 학습 (0) | 2021.08.31 |
| 1부 4.2 머신 러닝 모델 평가 (0) | 2021.08.30 |
| 1부 4.1 머신 러닝의 네 가지 분류 (0) | 2021.08.30 |