[머신러닝 기초] 15일차 #3
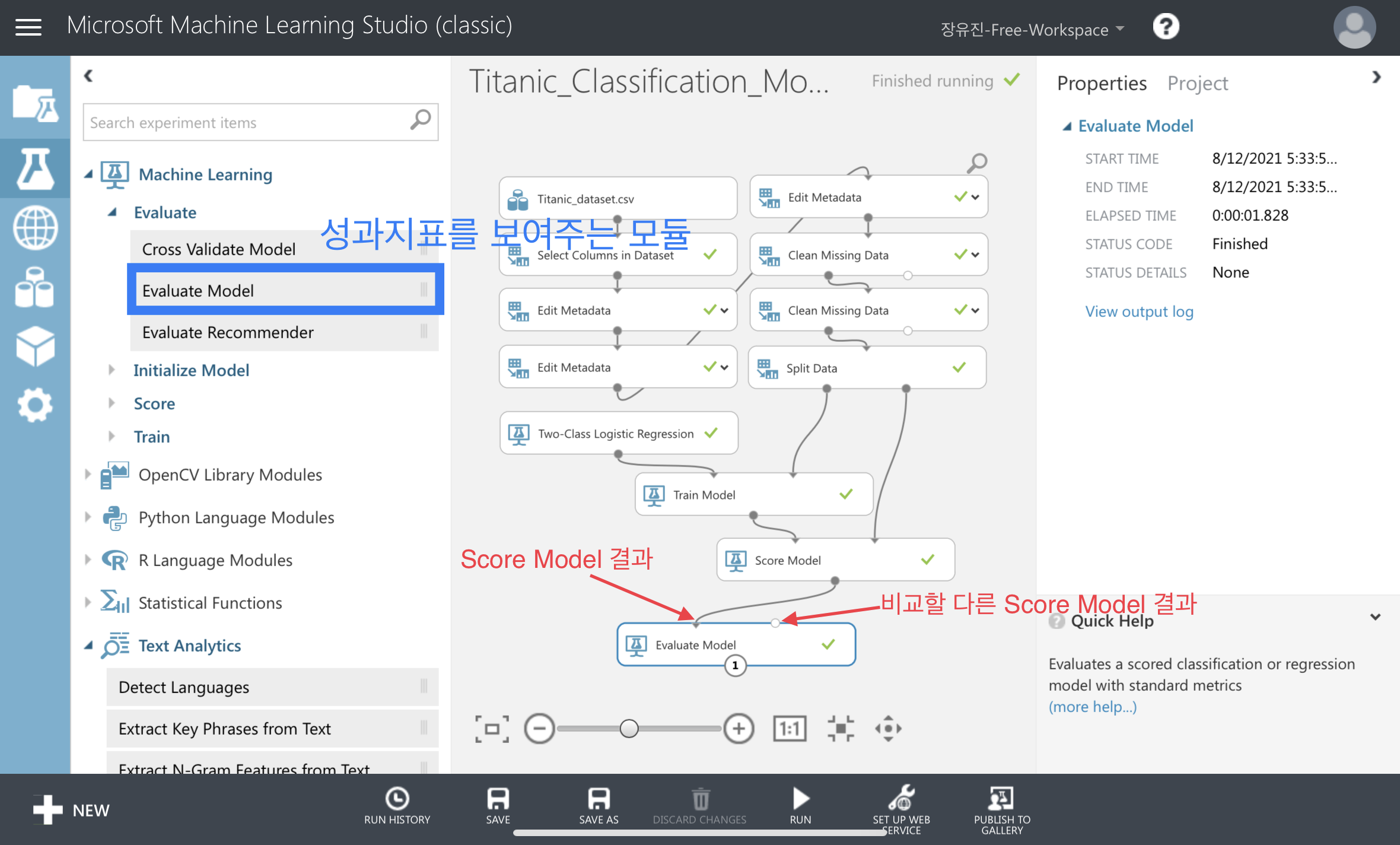
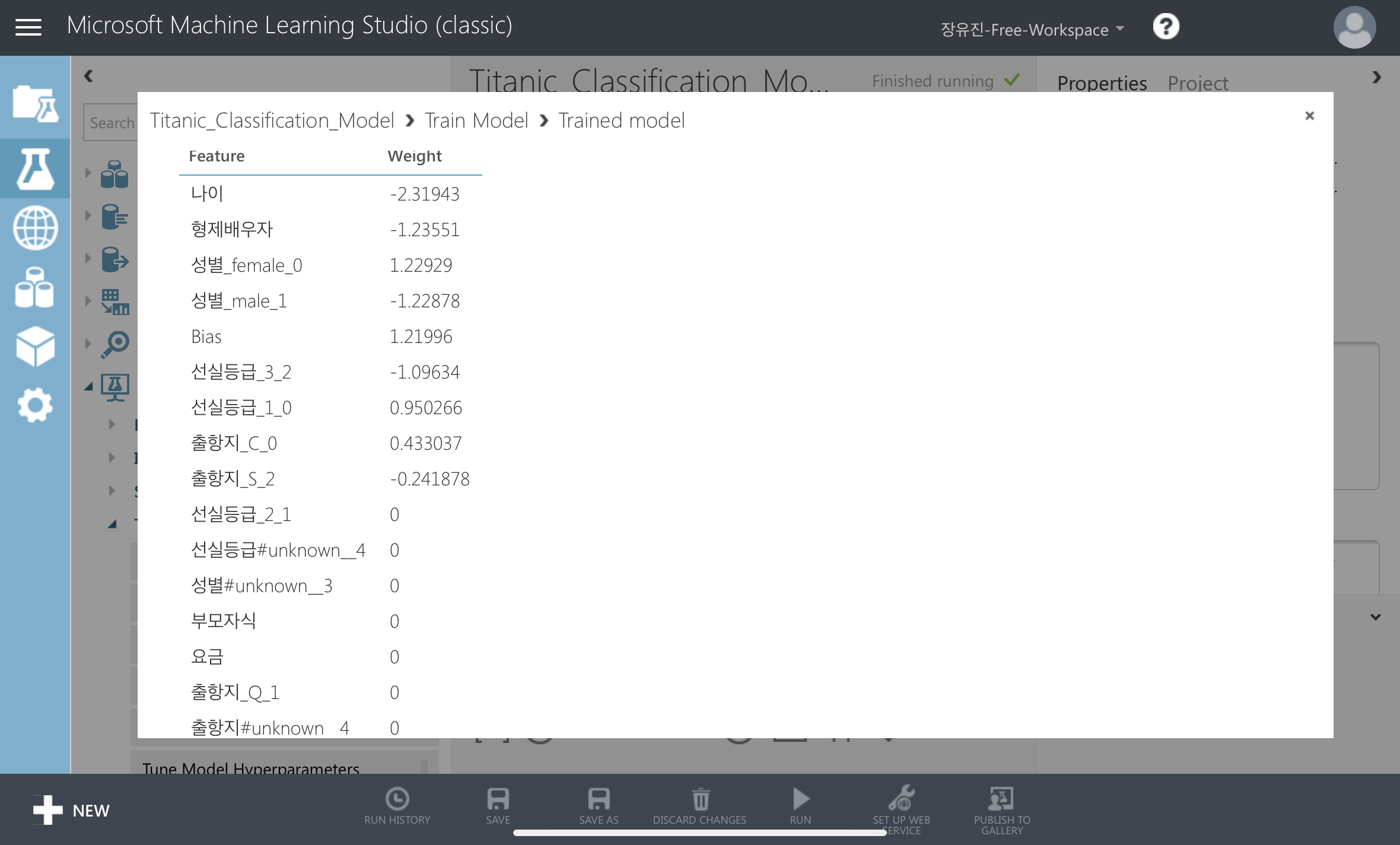
🔸날짜🔸 2021.08.10(화) 🔸제목🔸 [34] 분류 모델 지표의 의미와 계산법 : True Positive, False Posivite, True Negative, False Negative 🔸내용🔸 metric 학습 완료된 모델의 성능이 얼마나 되는지 숫자로 표현 학습 모델에 따라 살펴봐야하는 지표도 달라짐. 분류의 metric 1) True Positive(TP) 모델이 예측한 게 True이면서 예측이 맞았을 때 2) False Positive(FP) 모델이 예측한 게 True이면서 예측이 틀렸을 때 3) False Negative(FN) 모델이 예측한 게 False이면서 예측이 틀렸을 때 4) True Negative(TN) 모델이 예측한 게 False이면서 예측이 맞았을 때 1) Accura..